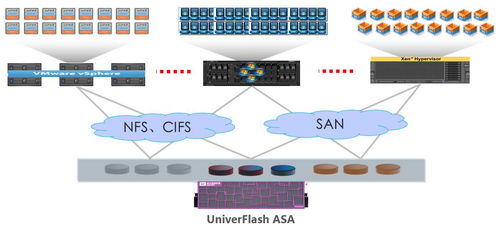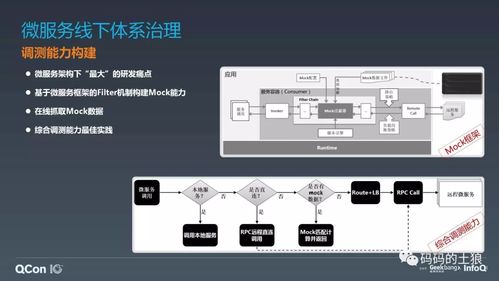
随着数字化转型的深入,后端数据库技术已从单一的关系型数据库发展为多元化的生态系统,以满足不同场景下的数据处理与存储需求。当前主流的数据库选择和实践呈现出明显的分层和场景化特征。
一、核心存储层:关系型与非关系型并存
1. 关系型数据库(RDBMS)仍是中流砥柱
- MySQL/PostgreSQL:作为开源领域的双雄,MySQL凭借其成熟生态和性能优势,在Web应用中占据主导地位;PostgreSQL则以其强大的功能(如JSON支持、GIS扩展)、严格的SQL标准兼容性和可扩展性,在复杂业务系统和新兴应用中快速增长。
- 云托管服务:AWS RDS、Google Cloud SQL、Azure Database等云服务提供了免运维、自动备份、读写分离等托管能力,大幅降低了运维成本。
2. 非关系型数据库(NoSQL)的多元化发展
- 文档数据库:MongoDB因其灵活的JSON-like文档模型和强大的查询能力,成为处理半结构化数据(如用户配置、内容管理)的热门选择。
- 键值存储:Redis作为内存数据库,以其超高性能支撑缓存、会话存储和实时排行榜等场景;Amazon DynamoDB则在云原生分布式键值存储领域表现突出。
- 宽列存储:Cassandra和ScyllaDB为海量时间序列数据、物联网数据提供高写入吞吐和线性扩展能力。
- 图数据库:Neo4j在处理社交关系、推荐系统、欺诈检测等高度关联数据时具有天然优势。
二、数据处理与分析层:实时与批处理的融合
1. 数据仓库的现代化演进
- 云数仓成为主流:Snowflake、Google BigQuery、Amazon Redshift等完全托管的云数仓,实现了存储与计算分离,支持PB级数据的快速分析。
- 实时数仓兴起:Apache Druid、ClickHouse等OLAP数据库能够对实时流数据进行亚秒级查询,满足监控、BI等实时分析需求。
2. 流处理平台的集成
- Apache Kafka不仅作为消息队列,其Kafka Streams和KSQL提供了实时流处理能力,形成“事件流中心”。
- Apache Flink凭借其精确一次处理语义和低延迟特性,成为复杂事件处理和实时ETL的重要选择。
三、新兴趋势与架构模式
1. 多模型与多数据库并存
现代架构常采用“多数据库”策略,根据数据特性选择最佳存储。例如:用户关系用图数据库、会话数据用Redis、交易记录用PostgreSQL、日志用Elasticsearch,通过服务化接口统一访问。
2. 云原生与Serverless数据库
Amazon Aurora、Azure Cosmos DB等云原生数据库提供了全球分布、自动扩展等能力;Serverless数据库(如Amazon Aurora Serverless)实现了按使用量计费,进一步优化资源利用率。
3. 数据网格与去中心化治理
数据网格(Data Mesh)理念倡导将数据视为产品,由领域团队负责其生命周期,推动了数据库管理的去中心化,强调标准化接口而非统一技术栈。
四、存储支持服务的全面化
1. 备份与容灾
- 跨区域复制、时间点恢复(PITR)成为云数据库标准功能。
- 工具如Percona XtraBackup、pgBackRest提供物理备份能力。
2. 监控与可观测性
- Prometheus + Grafana监控数据库性能指标。
- 慢查询分析工具(如pt-query-digest、pgstatstatements)持续优化性能。
3. 迁移与同步工具
- Debezium实现CDC(变更数据捕获),将数据库变更实时流式同步到数据仓库或缓存。
- AWS DMS、Google Database Migration Service简化上云迁移。
五、选型建议与实践考量
选择数据库时需综合评估:
- 数据模型:结构化程度、关系复杂度。
- 访问模式:读写比例、事务需求、并发量。
- 一致性要求:强一致性还是最终一致性。
- 扩展性:垂直扩展还是水平分片。
- 生态与团队技能:社区活跃度、工具链成熟度。
###
现代后端数据库生态已从“一刀切”走向“场景驱动”,形成了关系型、NoSQL、数据仓库、流处理平台协同工作的多层次架构。成功的实践不在于追求最新技术,而在于根据业务特性选择合适工具,并通过有效的治理与运维保障数据可靠性、安全性和性能。随着AI增强管理、自动化优化等技术的发展,数据库将更加智能化和隐形化,让开发者更专注于业务逻辑创新。