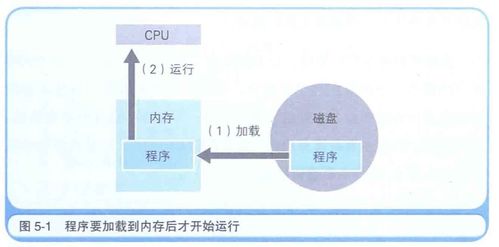
在现代分布式系统中,后端服务的性能直接决定了用户体验和业务承载能力。特别是在数据处理与存储支持服务这类核心基础设施上,性能瓶颈往往成为系统扩展的掣肘。因此,系统性的性能压测不仅是上线前的必要环节,更是持续优化与架构演进的重要依据。本文将探讨针对此类服务的压测实践,涵盖目标设定、场景设计、工具选型、瓶颈分析与优化策略。
一、明确压测目标与关键指标
性能压测的首要步骤是定义清晰的目标。对于数据处理与存储服务,核心指标通常包括:
- 吞吐量:单位时间内成功处理的请求数(QPS/TPS),特别是在数据写入、查询、聚合等场景下的峰值能力。
- 响应时间:P50、P95、P99等百分位延迟,直接关联用户体验。对于存储服务,P99延迟的稳定性尤为关键。
- 资源利用率:CPU、内存、磁盘I/O、网络带宽的使用率,目标是找出资源瓶颈(如CPU密集型计算或I/O等待)。
- 错误率:在高压下服务返回错误(如超时、连接失败、数据不一致)的比例。
- 系统稳定性与恢复能力:在持续负载下服务是否出现性能劣化,以及负载骤降后能否快速恢复。
二、构建贴近生产的压测场景
压测场景的设计必须模拟真实业务流量。对于数据处理与存储服务,需重点关注:
- 数据模型与容量:使用与生产环境相似的数据结构、索引和初始数据量。压测数据库时,预填充一定规模的数据(如TB级别)以模拟线上状态。
- 请求混合比例:根据业务特征,合理配置读写操作的比例(例如,写入:查询 = 3:7),并包含复杂查询、批量操作、事务处理等关键路径。
- 流量模型:采用阶梯增压、波浪型或稳态持续压力等模式,分别验证服务的弹性伸缩极限和长稳运行能力。
- 依赖服务模拟:使用像WireMock、MockServer等工具模拟上下游服务,避免压测期间对真实外部系统造成影响。
三、工具链选择与实施
选择合适的工具能事半功倍。常见的压测工具包括:
- 负载生成:JMeter、Gatling、k6等适用于API层压测;对于存储层,亦可使用专用工具如sysbench(数据库)、YCSB(NoSQL)。
- 监控与可观测性:这是压测的“眼睛”。需整合基础设施监控(如Prometheus+Grafana采集服务器指标)、应用性能监控(APM,如SkyWalking, Pinpoint)以及数据库慢查询日志、连接池状态等。
- 分布式压测:当单机无法产生足够压力时,需采用分布式压测集群,并确保时钟同步和结果汇聚。
实施时,应遵循从单接口到混合场景、从单服务到全链路、从测试环境到生产影子压测的渐进过程。
四、典型瓶颈分析与优化策略
压测的核心价值在于暴露问题。针对数据处理与存储服务,常见瓶颈及应对思路包括:
- 数据库连接池耗尽:表现是大量请求超时。优化方法包括调整连接池大小(如HikariCP配置)、引入读写分离、优化事务范围、或使用连接更轻量的驱动。
- 慢查询与索引失效:高并发下,一个未走索引的查询可能拖垮整个实例。通过分析慢日志,针对性添加或优化复合索引,避免全表扫描。对于复杂聚合,考虑预计算或使用物化视图。
- 磁盘I/O瓶颈:表现为IO等待过高,TPS上不去。可考虑使用SSD、增加磁盘阵列、优化日志写入策略(如组提交),或对热数据进行缓存(如Redis)。
- 序列化/反序列化成本高:特别是在处理大量数据对象时。可评估更高效的序列化协议(如Protobuf、Msgpack),或优化Java对象转换流程。
- 锁竞争激烈:在高并发更新场景下,行锁、表锁甚至分布式锁都可能成为瓶颈。优化策略包括减少事务粒度、使用乐观锁、或通过队列异步化写操作。
- 内存与GC压力:长时间压测可能引发内存泄漏或频繁Full GC。需分析堆内存使用,优化数据结构和缓存策略,调整JVM参数。
五、建立性能基线与持续回归
每次重大迭代后,都应进行性能回归测试,与历史基线(Baseline)对比,防止代码变更引入性能衰退。将性能测试纳入CI/CD流水线,作为准出标准之一。
对数据处理与存储支持服务的性能压测,是一项贯穿于设计、开发与运维全周期的系统工程。它不仅是发现瓶颈的技术手段,更是推动架构合理化、资源精细化管理的驱动力。通过科学的压测实践,团队能够构建出既满足当前业务峰值,又具备弹性伸缩潜力的稳健后端服务,为业务的快速发展奠定坚实的技术基石。